首页
人脸识别项目
更新-260317 | 发布-260316
从一个想法到实现的过程,供参考。
想法
想做一个人脸识别项目,识别摄像头拍到的人脸是张三还是李四。项目做出来后可用于:
- 刷脸开门:待项目逐步成熟后,替代当前部分房间的密码开门、钥匙开门。能力要持平商业产品,价格要有竞争力。
- 刷脸打卡:会议等签到可使用刷脸来打卡。
- ……(更多用途待畅想)
思考如何实现
真的能做到刷脸开门、刷脸打卡等,肯定还有很多功能要做的。比如要接喇叭说:你好!张三。核心功能还是:有个人脸库(存放若干人脸照片),和待识别图片比对,从而识别出是张三李四。
当前约定在华为开发板1 上实现。可能当前阶段还用不到 vibe coding 相关工具比如 Claude Code。先问问 deepseek 和 豆包,比如:
人脸识别系统
1、基于昇腾 200I DK A2 开发板。
2、请推荐人脸识别模型,小型、轻量即可。
3、将模型转换成开发板要求的 om 模型,由我用 ATC 工具来做。
4、识别最多10张不同的脸。
5、用 Python 实现。
6、要使用开发板的 ACL 语言,以便使用开发板的 NPU 算力做推理
请给出样例代码。
AI 给了 3 个模型:
- SCRFD,人脸检测
- VanillaCNN,关键点对齐
- SphereFace,特征提取
在开发板上执行给的代码,也不大对。
继续和AI交流,比如用一个模型,……。AI推荐 MobileFaceNet。在上网搜索,得到一个开源项目:夜雨飘零/Pytorch-MobileFaceNet↗。
本地电脑体验
夜雨飘零/Pytorch-MobileFaceNet↗ 貌似可以直接运行。在 macOS 笔记本上启动 终端,新建空目录,在空目录中执行 git clone 下载源码:
mkdir ailab
cd ailab
git clone git@gitee.com:yeyupiaoling/Pytorch-MobileFaceNet.git
主要做了以下操作,就可在 macOS 笔记本上跑通:
- 激活笔记本上的 Python 虚拟环境,尝试运行,并安装缺少的 Python 包。
-
修改 GPU 相关为 CPU,因为 macOS 笔记本不带 GPU。和 AI 交流后得到的主要修改有:
# self.device = torch.device("cuda") self.device = torch.device("cpu") ... # self.model = torch.jit.load(mobilefacenet_model_path) self.model = torch.jit.load( mobilefacenet_model_path, map_location=torch.device("cpu") )有多处类似地方,要做相应修改。
执行以下命令得到推理结果:
python3 infer.py --image_path=dataset/test.jpg
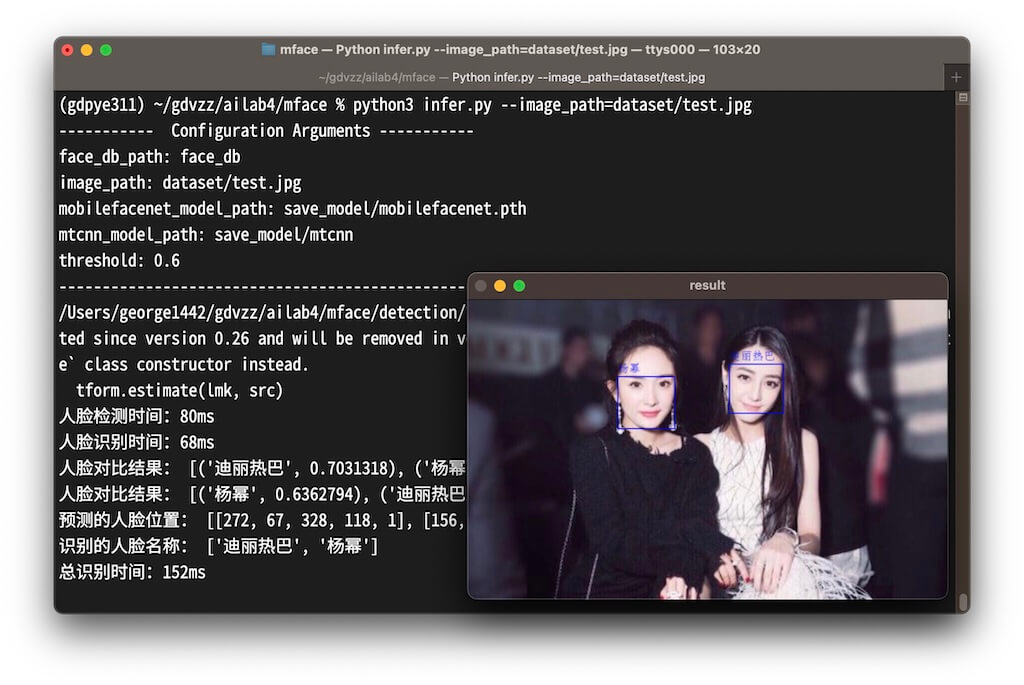
开源项目说明中
--image_path=temp/test.jpg,应改为--image_path=dataset/test.jpg。
弹出的图片窗口,可按空格后关闭。
开发板体验
新建用户
在开发板上新建用户 gdv2,从零开始。该步骤可选,不是必须。
-
先在本地电脑的终端 App中执行以下命令登录开发板,初始密码是
Mind@123。ssh root@192.168.137.100 -
登录后在终端(虽然终端是在本地电脑上,但已远程登录开发板,可理解为在开发板上了)以 root 用户身份执行命令新建用户 gdv2。
adduser --home /home/gdv2 --shell /bin/bash gdv2如不确定当前是否为
root用户,可执行命令whoami。如显示 root 则OK。如不是,可执行命令su - root切换到 root 用户,root 用户的初始默认密码是Mind@123。新建用户的命令中, gdv2 是用户名,可以是其他取值,比如 zhangsan。则命令相应变为
adduser --home /home/zhangsan --shell /bin/bash zhangsan。执行adduser --help可获得帮助,尤其是记不住的命令行相关参数。 -
再执行如下命令将新建的 gdv2 用户加入 sudo 组,可允许 gdv2 用户执行某些要超级用户 root 才能执行的命令,比如
sudo apt install 某软件(安装某软件)。adduser gdv2 sudo
创建环境
以下均以新建用户 gdv2(或其他用户名) 运行。执行以下命令切换到 gdv2 用户:
su - gdv2
开发板上已安装 conda。用 conda 创建新的虚拟环境,用于体验人脸识别。新建的虚拟环境可少一些这样那样环境相关的问题,同时不干扰其他已正常运行的其他项目,建议要新建虚拟环境来体验人脸识别。
-
连外网。有多种方式:
开发板先要连接外网。创建虚拟环境、安装 Python 包,都需要访问外网。
可共享本地电脑的网络(可以上外网的)给开发板,详情可参考:通过PC共享网络联网(Windows)↗。亲测可行。如不大行就重新操作一次即可。
还可以再插一根可以上外网的网线,到开发板的上下排列的2个网口的下面那个网口。按开发板默认镜像的设置,下面那个网口是 DHCP(自动分配网址)。插上网线后,可以在终端执行
ifconfig | grep 172(通常校园网的IP地址是 172.xxx.xxx.xxx),如果能看到 172 开头的 IP 地址,则表示连接成功啦。 -
新建虚拟环境。执行以下命令:
conda create -n mface python=3.9mface 是虚拟环境的名字。可以是其他名字。
和AI交流,建议创建 Python 3.9 环境。
-
激活虚拟环境。执行以下命令:
conda activate mfacemface 是刚创建的虚拟环境的名字。
可执行
conda env list查看有哪些 Python 虚拟环境。可能提示 conda shell 相关错误。按屏幕提示信息处理就好:先执行
conda init bash,再从本地电脑终端重新ssh gdv2@192.168.137.100。激活后命令行提示符行首会出现
(mface)字样,表示当前已在 mface 虚拟环境中。 -
安装必要的 Python 包。执行以下命令:
pip3 install opencv-python torch torchvision scikit-image tqdm scikit-learn确保是在 mface 环境中(即行提示符行首有
(mface)字样)安装这些 Python 包。
体验人脸识别
执行以下命令,下载源代码:
mkdir ailab # 新建目录,名称随意
cd ailab
git clone git@gitee.com:yeyupiaoling/Pytorch-MobileFaceNet.git
对源代码做修改:
- 修改 GPU 相关为 CPU,因为开发板没有 GPU(对应的是 NPU)。如何修改请参考 本地电脑体验。
- 和AI交流,将 infer.py 中最后的
predictor.draw_face(args.image_path, boxes, names)改成写文件。因为 ssh 远程登录开发板无法如本地电脑体验那样显示结果图片窗口。
执行以下命令体验人脸识别:
python3 infer.py --image_path=dataset/test.jpg
可用本地电脑上的 MobaXterm(仅支持 Windows) 软件打开结果图片文件查看。或者使用
scp命令将结果图片文件复制到本地电脑后查看。
还可以做以下操作体验更多:
- 在开源项目的目录
face_db中新增一张图片,比如张凌赫.jpg。 - 再找一张不同的张凌赫图片,放在开源项目的目录
dataset中,比如zhanglinghe.jpg。 - 执行命令
python3 infer.py --image_path=dataset/zhanglinghe.jpg并查看识别结果。 - 再找更多照片,但这些照片的人不在
face_db中,运行推理程序,查看识别结果(期望结果是 unknown)。
使用 NPU 推理
开发板体验 只是把开发板当做普通计算机使用。还要进一步用到开发板的 AI 算力(NPU),以加快推理(识别)速度。
可参考以下资料,对上述程序做修改,使用到开发板的 NPU 算力做推理:
- 昇腾样例代码↗。可参考 inference、python、cplusplus 等子目录中的样例。
- AscendCL应用开发入门↗
- AscendCL应用开发指南(Python)↗